Een computer kun je leren schaken zonder gebruik te maken van Machine Learning. Computers zijn daar ook nog eens best wel goed in. Zie als voorbeeld Deep Blue die een grootmeester versloeg, al in 1997. Zijn de schaakcomputers die wél Machine Learning gebruiken dan AI, en zijn de schaakcomputers die dat niet gebruiken dan niet kunstmatig intelligent? Deep Blue, kan ik wel verklappen, gebruikte voor zijn prestatie geen Machine Learning technieken.
Anderzijds is het ook discussieerbaar of alle Machine Learning toepassingen onder AI zouden moeten vallen. Een klassiek gereedschap uit de statistiek is de lineaire regressie. Hierbij modelleer je de relatie tussen variabelen in een dataset, waarna je voorspellingen over nieuwe data kunt doen. De machine leert deze relatie zelf op basis van een algoritme en de ingegeven data. Dat maakt het overduidelijk een vorm van Machine Learning. Toch klinkt een rechte lijn trekken niet ontzettend intelligent.
Dat brengt me bij het onderwerp waar ik dieper op in wil gaan in dit artikel: de Random Forest, ofwel het willekeurige bos (wat zijn Nederlandse vertalingen toch mooi soms -kuch). De Random Forest is in het huidige landschap van Machine Learning en AI een underdog. Dat maakt het echter niet minder krachtig als gereedschap in het arsenaal van de Data Scientist.
Decision Trees
Het gereedschap dankt zijn naam aan het gebruik van bomen. Niet die organische, maar wel zo een waar je beslissingen mee kunt nemen als je de takken volgt: een Decision Tree. Een beslissingsboom is een speciaal geval van stroomdiagram, waarbij geen cykels voorkomen. In deze context gaat het ook nog om een speciaal geval van een beslissingsboom. Bij zo’n boom staat er op elke knoop een kenmerk van de data. Elke vertakking splitst de data op aan de hand van een voorwaarde op dat kenmerk.
Stel we het hebben over het weer gedurende enkele dagen, en een van de datakolommen die we hebben is de temperatuur. Dan kan een vertakking bij de knoop ‘temperatuur’ de data opdelen in momenten met temperatuur boven en onder de 15 graden. Zie de afbeelding met voorbeeld van een heel simpele boom hieronder. De weergave is van de stam bovenaan naar de bladeren onderaan (nog een verschil met de organische variant). Zoals te zien is kan een opsplitsing zowel met een ja/nee vraag (categorie) als met een voorwaarde op een reëel getal. Dit is een grote kracht van Decision Trees ten opzichte van veel andere (geavanceerdere) methodes.
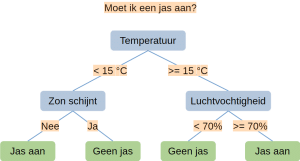
Hoe ‘leert’ een computer welke splitsingen gemaakt moeten worden? Dat gaat met behulp van een ‘gierig’ (greedy) algoritme. Bij elke knoop worden er twee keuzes gemaakt: welk kenmerk moet er gebruikt worden en waar moet het opgesplitst worden. Het algoritme beslist door te kijken welke optie de data in zo uniform mogelijke groepen opsplitst. Uniform wil zeggen enkel punten van één uitkomst (‘Jas aan’ of ‘Geen jas’). Dit heet gierig omdat het wel lokaal de optimale oplossing is, maar het geeft geen garantie dat de boom in zijn geheel (globaal) optimaal is.
Als de data heel ‘schoon’ is, dan werkt zo’n boom heel goed. Vaak is onze data echter een stuk minder rechtlijnig en bevat het grijze gebieden. Als we de boom alle vrijheid geven om te groeien dan leidt dit tot overfitting. Dat wil zeggen dat onze boom de data perfect leert na te bootsen. Liefst willen we dat de boom een algemeen model vormt dat ook met nieuwe data nog goed werkt.
Random Forests
Het bos dat we van de Decision Trees kunnen maken lost dit op. Door meerdere bomen over de beslissing (wel/geen jas) te laten ‘stemmen’ voorkomen we overfitting en kan het model de data beter generaliseren. De vraag is: hoe combineren we dan meerdere bomen? Als we elke boom met datzelfde gierige algoritme laten groeien worden ze allemaal identiek.
Daar komt de willekeur te pas. Die wordt op twee belangrijke plekken ingevoerd. Ten eerste passen we een bekende techniek uit de statistiek toe: bootstrapping, ook wel bekend als bagging (bootstrap aggregating) in de Machine Learning wereld. Dit houdt in dat we verschillende steekproeven uit de originele data halen. Daarbij is het toegestaan om meermaals hetzelfde datapunt te kiezen (sampling with replacement). Op deze manier creëren we een aantal van elkaar verschillende en onafhankelijke ‘versies’ van de originele dataset.
De tweede manier waarop de bomen in het bos verschillend van elkaar gemaakt worden is door willekeur in de knopen te bouwen. Normaliter kiezen we bij iedere knoop in een Decision Tree het beste kenmerk uit alle kenmerken van de data. Bij een Random Forest is het gebruikelijk om dit te beperken: er komt slechts een willekeurige subset van de kenmerken in aanmerking bij iedere knoop. Meestal beperken we het aantal tot de vierkantswortel van het totale aantal kenmerken.
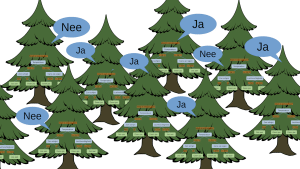
Samen zorgt dit ervoor dat alle bomen in het bos anders zijn. Is het bijvoorbeeld 15 graden en bewolkt, dan zouden sommige bomen ‘jas aan’ stemmen en sommige ‘geen jas’. De uitkomst van iedere boom wordt vervolgens samengevoegd door te kijken naar de meerderheid. Overigens valt dit aan te passen: men kan bijvoorbeeld ook eisen dat 80% van de bomen het erover eens zijn dat je geen jas aan hoeft. Dit is een soort waarschijnlijkheid drempelwaarde (probability threshold) die handmatig ingesteld kan worden naar gelieve de specifieke toepassing.
Feature engineering
We hebben nu gezien wat een Random Forest is en hoe die werkt. Er is echter nog een heel belangrijk aspect waar we tot nu toe overheen gekeken hebben. De kenmerken (features) van de data die we aan het model geven zijn ontzettend belangrijk. Zoals bij alle Machine Learning geldt: excrementen erin betekend excrementen eruit. Als de data geen informatie bevat kun je het er ook niet uit halen. Stel dat we het weer proberen te voorspellen aan de hand van astronomische waarnemingen van Proxima Centauri: dan komen we natuurlijk niet zo ver. De verkoopcijfers van paraplu’s kunnen daarentegen wellicht wel correlatie vertonen.
Aan de ene kant kan de Decision Tree, en daarmee de Random Forest, goed overweg met irrelevante kenmerken. Hij zoekt immers bij iedere knoop een optimale splitsing. Dit stelt ons in staat om te onderzoeken welke kenmerken belangrijker zijn dan anderen. Anderzijds is het voor optimale prestaties beter om te focussen op belangrijke kenmerken met veel voorspellende waarde. Als we de set kenmerken te veel ‘verdunnen’ moet het model zijn aandacht te veel verdelen. Hij kijkt immers bij iedere knoop slechts naar een willekeurige subset van kenmerken.
Dit betekent dat het zich loont om veel aandacht te besteden aan het bijeenzoeken van de optimale set kenmerken. Dat kan ook betekenen dat je kenmerken samenvoegt of transformeert. Dit proces staat bekend als feature engineering.
Random Forests als AI
Al met al best een slim in elkaar gestoken algoritme, dat met doeltreffende inzet van Machine Learning en gerichte inzet van willekeur een verrassend krachtig geheel vormt. En dat wordt bereikt met simpele en heel inzichtelijke basis ingrediënten, de Decision Trees. Zoals benoemd zijn Decision Trees alleenstaand al een voorbeeld van Machine Learning. Kan dit dan als AI worden beschouwd? Dat hangt uiteindelijk af van hoe je AI definieert. Tot dusver is dat een subjectieve vraag waar iedereen voor zichzelf antwoord op moet geven.
Mijn persoonlijke kijk hierop is dat we de term AI beter zouden loskoppelen van Machine Learning. Om een kunstmatig systeem ‘intelligent’ te noemen zou je dan kijken naar bepaalde kwaliteiten: niet alleen vermogen om te leren, maar bijvoorbeeld ook beredeneren, problemen oplossen, perceptie en besluitvorming.