Wat is Matillion?
Matillion is een visuele low-code ELT tool, waarmee je datapipelines kunt bouwen door eenvoudig blokjes aan elkaar te verbinden. Elk blokje voert een (SQL-)transformatie op je data uit. Door meerdere blokjes aan elkaar te verbinden bouw je in no-time een datapipeline.
In deze low-code omgeving wordt het lastig om kwaliteit te waarborgen als je datapipeline complexer wordt. Hierdoor liep ik tegen de centrale vraag van dit artikel aan: Hoe waarborg je kwaliteit tijdens je ontwikkelproces in Matillion?
Aanpak: Testen van de pipeline
Testen is een methode die in software engineering veel wordt gebruikt om te controleren of je software na een verandering nog correct functioneert. Dit principe wilde ik ook toepassen op mijn datapipeline om de kwaliteit te waarborgen. Mijn aanpak was als volgt:
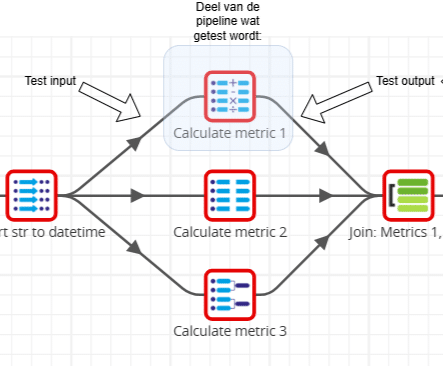
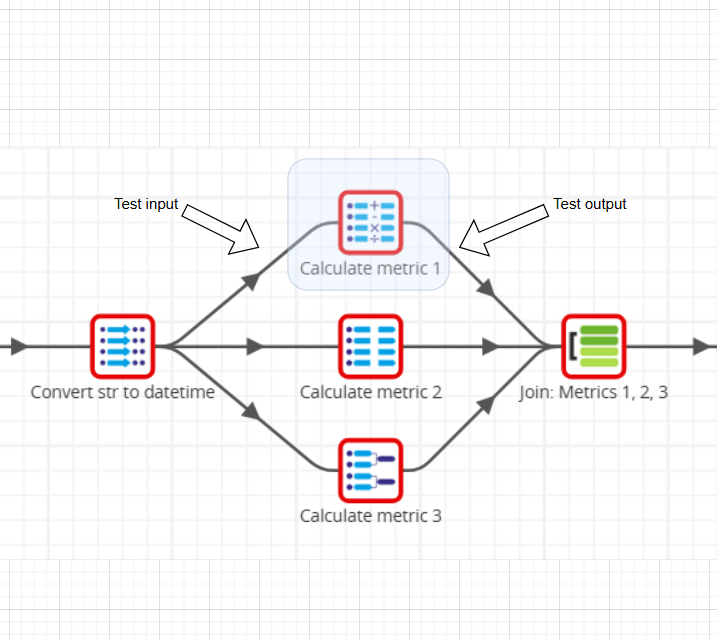
- Test input definiëren.
- Stuur deze input data door het deel van de pipeline dat ik wil testen.
- Vergelijk de daadwerkelijke output met de verwachte output.
Hieronder is weergegeven hoe dit zou kunnen werken:
Beperkingen van Matillion
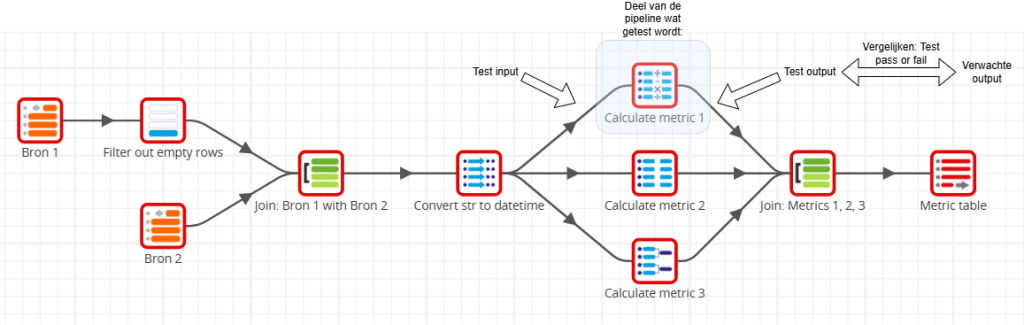
Bij deze aanpak liep ik echter tegen twee beperkingen van Matillion aan:
- Je kunt data in je pipeline alleen binnenhalen of wegschrijven doormiddel van Table input (e.g. Bron 1 en Bron 2) en Table ouput (e.g. Metric table)*.
- Je kunt pipelines alleen in hun geheel draaien.
Om Test input toe te voegen zou ik op die plek dus een Table input blokje moeten toevoegen, en dan de hele pipeline draaien. Voor elke andere test zou je dan ook een Table input en -output moeten toevoegen. Voor je het weet is je pipeline meer testblokjes dan functionele blokjes.
Oplossing: Integratietests
Om deze beperkingen te omzeilen, heb ik mijn test-cases opgeschaald naar integratietests. Hierbij draai ik de hele pipeline voor elke test. Door de integratietests specifiek toe te spitsen op bepaalde onderdelen, kan ik gericht de functionaliteit testen die ik wil valideren (in dit geval “Calculate metric 1”). Dit ziet er als volgt uit: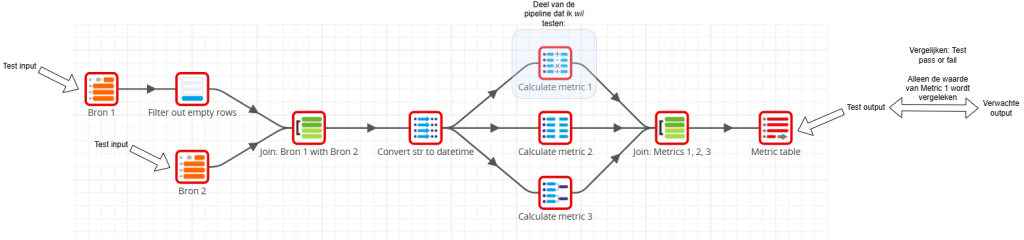
Doordat de pipeline de testinput rechtstreeks uit de Bron 1 en Bron 2 blokjes haalt, kan ik deze initialiseren doormiddel van SQL-queries. Hierbij moet ik opletten dat ik niet de echte operationele tabellen en data overschrijf. Daarom kies ik ervoor om de tabelnamen in mijn testen een prefix te geven, zoals “TEST_”.
Bijvoorbeeld:
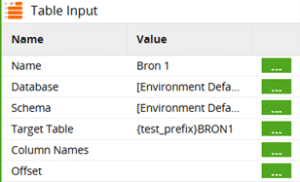 De table-input en –output blokjes in de pipeline moeten hiervoor dynamisch kunnen verwijzen naar de operationale tabellen of de test-tabellen. Daarom maak ik gebruik van een variabele tabelnaam voor Target Table, zoals {test_prefix}BRON1.
De table-input en –output blokjes in de pipeline moeten hiervoor dynamisch kunnen verwijzen naar de operationale tabellen of de test-tabellen. Daarom maak ik gebruik van een variabele tabelnaam voor Target Table, zoals {test_prefix}BRON1.
Waarbij in de SQL voorbeelden {test_prefix} gevuld wordt met “TEST1_” zodat er naar “TEST1_BRON1” verwezen wordt. Tijdens een operationele draai van de pipeline is {test_prefix} leeg, zodat er naar “BRON1” verwezen wordt. Dit maakt het dus mogelijk om integratietests te draaien zonder de operationale data aan te raken.
Conclusie
Deze testaanpak in Matillion maakt het mogelijk om de kwaliteit van mijn datapipelines consistent en auotmatisch te waarborgen. Dit bespaart mij veel tijd die anders naar handmatig testen zou gaan.
Deze testaanpak heeft ook beperkingen. Doordat bij elke test de hele pipeline draait duurt een test relatief lang, en is op kleinere schaal testen een grotere uitdaging.
Al in al levert deze testaanpak mij aanzienlijke kwaliteits- en tijdwinst op. Hierdoor heb ik meer ruimte om nieuwe functionaliteiten te ontwikkelen en kan ik verzekerd zijn dat mijn datapipeline correct functioneert na een aanpassing.
*Voor simpliciteit heb ik in dit verhaal enkel Table input en Table output genoemd. Er zijn meer blokjes waarmee je data kunt ophalen en wegschrijven. De functionaliteit van die blokjes is voor deze toepassing echter niet significant anders.