

Chaos Engineering
Chaos Engineering omvat het experimenteren op een systeem, om vertrouwen op te bouwen in het vermogen van het systeem om turbulente omstandigheden te kunnen weerstaan in een productieomgeving.
Binnen Chaos Engineering wordt gesproken over experimenten i.p.v. tests, aangezien het onbekende resultaten geeft. Het is dan ook niet bedacht om unit en integratietesten te vervangen, maar om samen te werken om hoge beschikbaarheid te creëren, klanttevredenheid te waarborgen en de business ‘up and running’ te houden. 100% uptime kan niet worden gegarandeerd, maar de situatie mag niet zo zijn dat een component dat faalt de beschikbaarheid van een volledig systeem kan beïnvloeden.
“Chaos doesn’t cause problems. It reveals them.” – Nora Jones
Simian Army
Er zijn ondertussen een aantal verschillende tools die helpen bij het simuleren van chaos. De meest bekende is de ‘Chaos Monkey’, een tool die onverwachte omstandigheden kan nabootsen (o.a. vertraging, uitval).
Naast de Chaos Monkey zijn er verschillende andere tools uitgebracht onder de noemer ‘Simian Army’; Een project om verschillende fouten en abnormale toestanden te detecteren.
Inmiddels wordt het Simian Army project niet meer actief onderhouden, maar is een deel van de functionaliteit verplaatst naar andere projecten. Hieronder staan een aantal ‘Monkeys’ beschreven, die nog steeds (al dan niet in een andere vorm of andere projecten) gebruikt worden.

Chaos Monkey
Chaos Monkey komt van het idee om een wilde aap los te laten in een data center (of cloud omgeving), die random instanties sloopt en kabels doorkauwt, terwijl de service voor de gebruiker zonder onderbrekingen draaiende wordt gehouden. Chaos Monkey maakt gebruik van verschillende ‘Forces of Chaos’ om deze situaties te simuleren:
– Graceful Restarts & Degradation
Het vermogen van een systeem of netwerk om (gelimiteerd) operabel te blijven. M.a.w. wanneer 1 node of instantie faalt, zorgt dit er niet voor dat het systeem plat gaat.
– Targeted Chaos
Het gecontroleerd bekijken wat en waar het fout kan gaan (bijv. door onderdelen van het systeem uit te zetten of veel consumers op 1 deel van het systeem toe te voegen). Dit onderdeel wordt in de ontwikkel-/testomgeving uitgevoerd, om storingen te ontdekken en op te lossen voordat er naar een volgende omgeving geschakeld wordt (bijv. de productieomgeving).
– Causing a Cascading Failure
Het triggeren van een storing in het systeem waardoor een keten aan fouten en storingen in het systeem ontstaan.
– Failure Injection
Het (door een ontwikkelaar) toevoegen van vertragingen (latency) of failures. Hierbij is monitoring van curiaal belang, om grip te krijgen op hoeveel gebruikers en verkeer er geraakt wordt.
– Chaos Automation Platform (ChAP)
Dit wordt gebruikt om storingen op microservice level in kaart te brengen. Het biedt monitoring aan om inzicht te geven in de experimenten. Een grafiek toont de experimentele groep en de controlegroep. Wanneer de experimentele groep te ver afwijkt van de controlegroep, wordt het experiment automatisch ingekort, wat de ontwikkelaars tijd geeft om lokaal en op debug niveau het probleem op te lossen.
Latency Monkey
De Latency Monkey tool wekt vertragingen op in RESTful services om te meten hoe de services omgaan met een slechtere performance. Daarnaast kan met extreme vertragingen gesimuleerd worden wat er gebeurd wanneer een node of service down is, zonder deze daadwerkelijk down te brengen. Deze tool is met name bruikbaar bij het testen van nieuwe services (wanneer een van de dependencies een storing heeft), zonder dat de rest van het systeem hier last van heeft.
De Latency Monkey code is nooit publiekelijk gereleased, maar is een onderdeel van de Failure Injection Testing (FIT) service geworden.
Failure Injection Testing (FIT)
FIT is geïntroduceerd door Netflix doordat er meer vraag was naar controle in de tools van de Simian Army. Het geeft met meer precisie aan wat er faalt en waar het mis gaat.
FIT is een opzichzelfstaande service, waardoor storingen (failure) geïnjecteerd kunnen worden door verschillende teams en experimenten met meer precisie kunnen worden uitgevoerd. Dit project is daarmee een doorontwikkeling van de Simian Army.
Conformity Monkey
Conformity Monkey zoekt instanties op die niet voldoen aan best-practices en stopt de processen. Bijv. wanneer een instantie niet toegevoegd is aan een auto-scaling groep, kan dit problemen geven in een productieomgeving. De Conformity Monkey stopt deze instantie en geeft de developers die verantwoordelijk zijn voor de service de mogelijkheid om de service op de juiste manier te herstarten.
Doctor Monkey
Doctor Monkey voert health checks op instanties uit en monitort vitale metrics (zoals CPU load, memory usage, etc.). Unhealthy instanties worden verwijdert.
Janitor Monkey
Janitor Monkey zoekt en verwijdert ongebruikte resources. De resources worden gecheckt a.d.h.v. een set configureerbare regels.
Security Monkey
Security Monkey was ontwikkeld als een uitbreiding op Conformity Monkey en checkt op mogelijke (security) kwetsbaarheden en overtredingen (o.a. security groepen en certificaten).
Bevindingen
Een aantal tools uit de Simian Army zijn verplaatst naar standalone projecten (o.a. Chaos Monkey en Conformity Monkey). Deze projecten zijn echter afhankelijk van het gebruik van Spinnaker (open source CI/CD tool, gebouwd door Netflix) en het gebruik van een MySQL database.
Veel van deze tools zijn met name getest (of ontwikkeld voor) AWS projecten. Niet alles is dan ook bruikbaar voor projecten op andere platformen.
Een andere tool is Gremlin, een Chaos Engineering platform. Dit platform is niet open source, maar de gratis standaard versie geeft mogelijkheden om kennis te maken met Chaos Engineering.
![]()
Gremlin
Gremlin leek na analyse de meest interessante tool om mee te starten binnen het huidige project. Één algemeen platform vanwaar verschillende typen aanvallen uitgevoerd kunnen worden. Een groot deel van de aanvalsvormen uit de ‘Simian Army’ is dan ook opgenomen binnen het platform, onder de toepasselijke naam ‘Gremlins’.
De community van Gremlin is aardig groot en er is dan ook veel documentatie en how-to’s te vinden. We hebben als test dan ook een van de bestaande tutorials gevolgd:
lokaal een VM opzetten, met daarop een Minecraft server geïnstalleerd, om aanvallen op deze server uit te voeren.
In de veilige omgeving van de Virtual Machine is het interessant om te kijken wat je met de attacks kunt bereiken. Het was dan ook snel gelukt om de server down te krijgen.
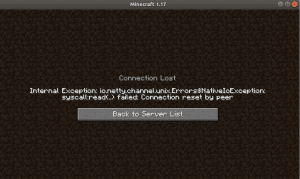
Ten slotte
Na wat basiskennis te hebben opgedaan met Chaos Engineering en het uitvoeren van de eerste aanvallen binnen een veilige omgeving is de interesse gewekt om het een en ander uit te proberen op een ontwikkel-/testomgeving.



